
Robots.txt is a file name you must have heard several times in the search engine optimization (SEO) world. If you’re wondering what robots.txt is and how to create one, you have to come to the right place.
In this post, we discuss what is robots.txt, why you may need one, and how to easily create a robots.txt file for your website.
What Is Robots.txt?
Try to understand robots.txt as the opposite of “sitemaps”.
It is apparently very good when search engines frequently visit your website and crawl it to index content in the search engine results pages, but sometimes it may not be what you want.
Sometimes, you may not want the search engine crawlers to visit your website and index certain contents or parts of your website. There may be several reasons for it; we will jump into those reasons shortly.
For now, the reasons are not important. What’s important is how you can stop search engine crawlers to not accessing certain parts of your website. This can be done with a robots.txt file.
Just like a sitemap tells the search engines what to index, a robots.txt tells search engines what not to index in the search engine results pages.
It is a plain-text file uploaded to the home directory of a website. A robots.txt file has particular instructions that search engine crawlers can understand. Generally, a robots.txt file contains the list of all URLs that you do not want search engine bots to access an index in search engines.
Reasons To Create a Robots.txt
As mentioned earlier, there are multiple reasons why someone would want to create a robots.txt file and stop search engine crawlers to access and index certain parts of your website.
Also, it may seem counterproductive to stop search engine crawlers from indexing your website, but it really isn’t. Most of the time, there are logical reasons why you wouldn’t want that, and that’s why almost every website you encounter would have a robots.txt.
Here are a few most common reasons why you may want a robots.txt.
To avoid wastage of server resources. When search engine crawlers crawl your website, they ask for robots.txt. And when they do not find a robots.txt file, they generate errors in logs — which ultimately lead to wastage of server resources.
To save bandwidth. As robots.txt can specify the pages you do not want to be indexed, it can save a lot of valuable bandwidth by stopping crawlers from needlessly spidering those webpages.
To avoid clutter in web statistics.
Refusing a bad robot and ill-behaved spiders to access your website’s content.
To secure sensitive information regarding your website that you do not want to be indexed in search engines.
How to Create Robots.txt?
Now that you know what robots.txt is and what are some of the logical reasons to have it, let’s see how to create a robots.txt file for your website.
First of all, it is important to know where you can find the robots.txt file.
It should always be in the website’s root folder. So if it isn’t already there in the website’s root folder, you will need to create one and place it there. You can do that with a simple FTP client.
A robots.txt file is a simple text-based file that you can open with Notepad or any other plain text editor.
How can you create one?
Simply open Notepad (or any other plain text editor), create a new file, and save it is robots.txt. You can then upload this file to the website’s root folder.
But having an empty .txt file won’t do much, right? That’s why you need to some codes that can help search engine crawlers understand what you want them to do.
This is how a sample robots.txt file looks like:

Let’s see how the syntax works:
The first line is usually the name of the user agent. In other words, it is the name of the search engine bot that you are trying to communicate with the robots.txt file. You should use “*” (asterisk) to communicate with all bots. On the other hand, you can also select a specific search engine bot, e.g., Googlebot.
The next lines are pretty self-explanatory. They contain instructions for the files and paths you want to allow or disallow. For instance, in the above example, you are instructing and allowing all bots to index the image upload directory. Similarly, in the next lines, you are also disallowing all bots to index the plugins and the readme.html file.
Different websites may have different-looking robots.txt files. It all depends on your specific needs and requirements. And you should also fashion your robots.txt file based on your needs.
Test Your Robots.txt File
Once you have finished creating a robots.txt file, it is always a good idea to check the syntax. It ensures that search engine crawlers are not able to access the URLs and specific contents of your website that you do not want to.
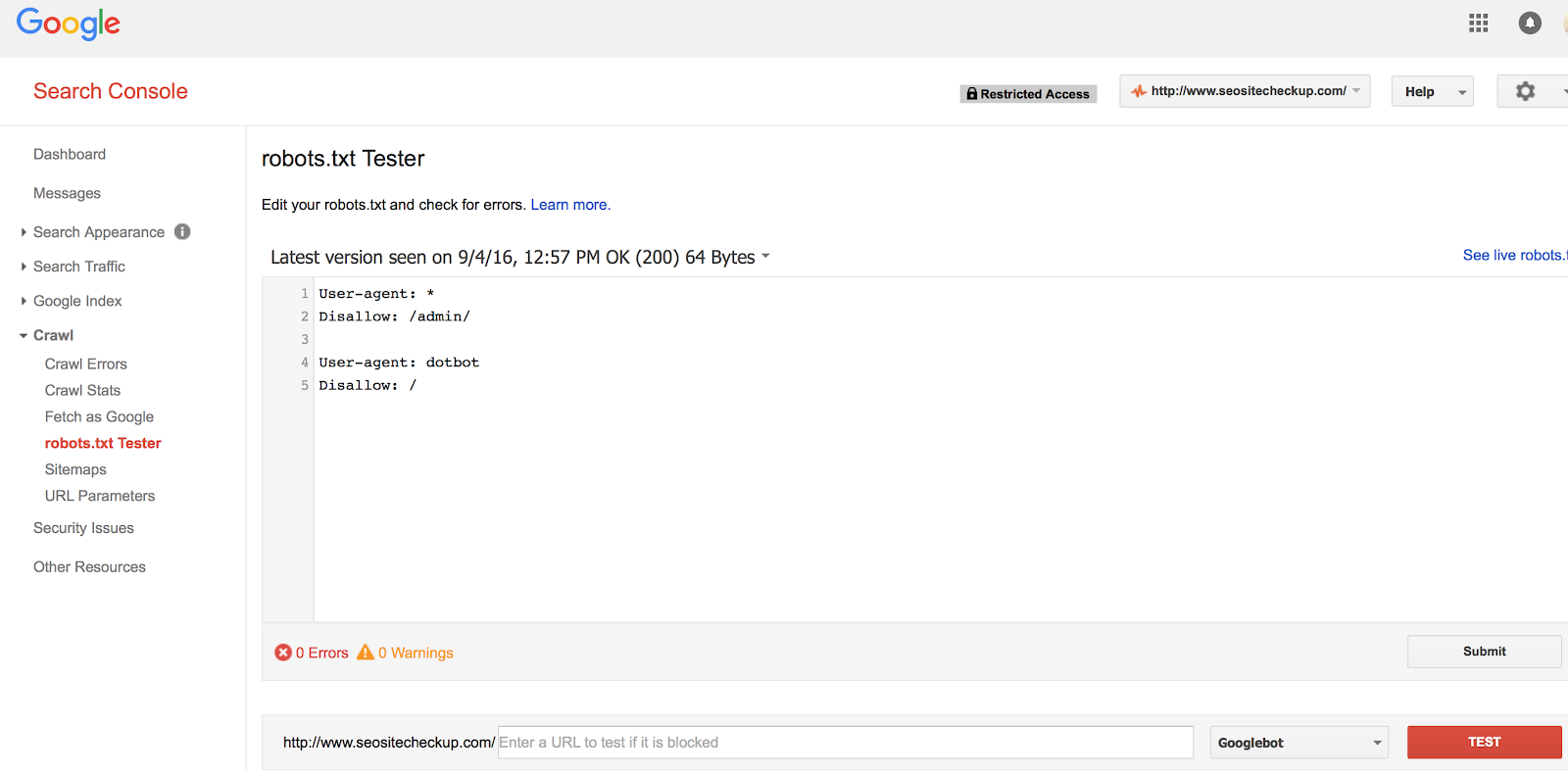
Google Search Console has a simple tool that lets you check the syntax and identifies any possible errors that your robots.txt file may have.
To access the tool, open Google Search Console. Select the ‘Crawl’ tab from the left sidebar and click ‘Robots.txt Tester’.
See the following screenshot for guidance.
Double-Check The File
Before uploading the robots.txt file, it is important to double-check the code. Make sure that you have thoroughly checked and confirmed the URLs you have included in the robots.txt file.
Sometimes, you may end up blocking URLs that you really didn’t want to. Therefore, it is a good idea to double-check the file to make sure that you are not accidentally blocking search engine crawlers from accessing any important webpage or URL.
Remember that the URLs mentioned in the robots.txt file may not get ranked in search engines.
Final Words
As discussed in this blog post, there are many reasons to create a robots.txt file. Almost every website has one.
First, determine what you want the search engines to index and what you don’t. Then create a robots.txt file based on the above-mentioned syntax. Check the syntax with robots.txt tester and double-check to make sure you aren’t accidentally blocking important parts of your website.
Once you have created the file with a plain text editor and finalized it, upload it to your website’s root directory. And that’s it.